前言
上一章中已经把渲染管线外的框架搭好了,也就是我们的 应用程序侧 的大致情况。这一章开始搭建渲染管线的基础!
1 渲染管线回顾
回顾一下在 RTR4 中提到的 GPU渲染管线 ,大致上是分为下面的部分:

如果不考虑虚线的两个阶段,那么整体做起来实际上也不会太难。不过比起常规的 图形 API ,这里除了常规的 Shader 以外, 无论是裁剪还是屏幕映射都要全部由自己的程式去实现,这是一个主要需要考虑的地方。从Vertex Shader 到 Pixel Shader 之间的步骤主要参考了 DX9 的渲染管线:
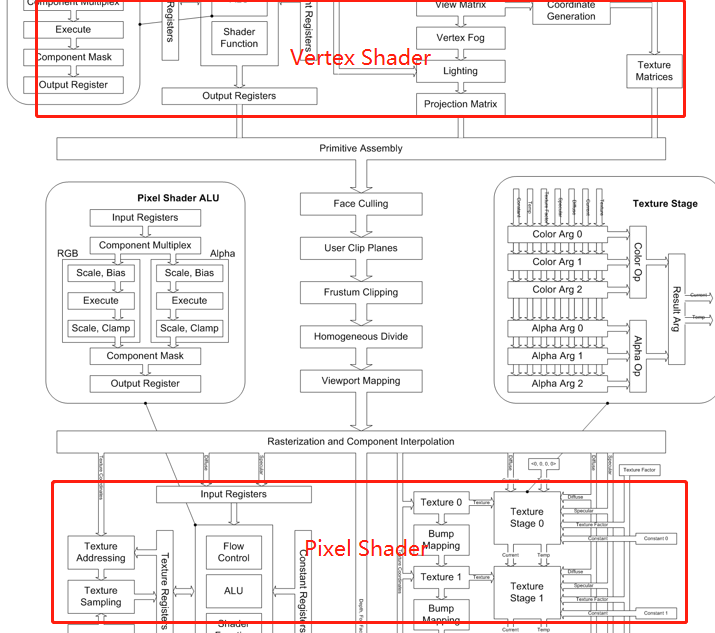
列出来的话大概分为这些部分:
- Application Stage
- Vertex Shader: Process on individual point
- Primitive Assembly: 把上一级的vertex分成三角形一组一组
- Face Culling
- Clipping (远近剔除)
- Homogeneous Divide
- Screen Mapping
- Rasterize
- Pixel Shader
2 管线管理
就像 DirectX12 可以设置 PSO 一样,我们也需要一个东西去管理目前管线的情况。例如去设置我们本次管线使用的 Shader, 以及渲染目标等。所以我这里新建了一个类用于管理这样的信息。
主要需要管理的部分为:
- **Flow Control: **设置渲染对象/使用的深度缓冲/渲染的矩形
- Data Control: 设置使用的常量以及纹理。类似于 DX12 绑定纹理的描述符,以及设置 32-bit Constants 。
相当于就是我们只有一个可变的 Pipeline State , 并且在运行时会根据需要去改变我们要渲染到的目标等。

上面主要是处理管线的状态,并没有涉及到管线的运行。这里因为我们实际上做的就是在封装一个自己的 软光栅API 了,那我就取一个简单的名字叫他 SimpleGL 。 那么管理整个图形 API 以及作为接口让外部呼叫的则是 SimpleGLCore 这样的类,我把它定义成下面这样:

主要的想法不是很复杂,就是提供一个 Draw Call 的接口,以及在里面呼叫所有渲染管线的步骤。
3 从应用到渲染管线
应用阶段一般我们是准备好需要用到的常量,以及我们的顶点数据,并且传入我们的整个渲染管线。就像我们在 DX12 中会设置 Input Layout 一样,我们这里肯定也是要设置好一个固定的输入格式,为了不复杂化这里直接写死了输入格式并包装为一个 Vertex 。
那么就像常规的图形 API 一样,我们只需要把所有顶点的信息以及索引传给 API, 剩下就是 API 做的事情了:

4 顶点着色器
顶点着色器我们是通过定义函数,并且以 std::function 方式储存在我们的管线状态管理类中。只要我们在外部设置好了指定的着色器,我们的 Draw Call 就会使用对应的着色器。
4.1 输入
这里我们传入了很多的顶点以及索引,不过目前在顶点着色器阶段我们是不在意图元的,也不用去理会索引提供的信息。 顶点着色器阶段可以在多线程的情况下单独操作所有的输入顶点。基本上就是下面这样的过程:
1
2
3
4
for(auto& vertex : vertices)
{
vertexShader(vertex);
}
4.2 输出
顶点着色器输出的数据我们之后会用于做插值,但不同的着色器组合可能会用到不一样的输出。这里顶点着色器它的输出分为两个部分,一部分是 图形API 需要用于特殊计算的位置信息 (一般我们着色器内会标明 SV_POSITION) 。另一部分则是大量的可插值的 32-bit 数据,我这里采用了大量的 float 。
![]()
这样的格式会方便我们之后去进行插值的计算。当然我们在着色器中是不会使用这种看起来比较简陋的格式的,因为我们可能会需要对 向量/矩阵 去进行操作,不过这并不是一个大问题。这是一个雏形的类,在着色器操作中我们不一定需要使用它,只需要定义一个全都由 float 组成的数据结构就可以了,整个操作流程就是这样:
- 为特定顶点着色器设置一个单独的 VertexOutput 类型
- 在顶点着色器中用这个类型操作
- 在函数返回前用 memcpy 把 VertexOutput 的结果储存到 PixelIn
一个顶点着色器就差不多是下面这样:
1
2
3
4
5
6
7
8
9
10
11
PixelIn defaultVS(Vertex vin)
{
VertexOutDefault vout;
vout.a = xxx
vout.b = xxx
PixelIn output;
memcpy_s(&output, sizeof(PixelIn), &vout, sizeof(VertexOutDefault));
return output;
}
4.3 裁剪空间位置信息
在最贴近 GPU 的工作方式的情况下我们的顶点着色器应该输出的是 裁剪空间, 而不是 NDC 空间。 也就是说结果不应该要除以 w 。 主要原因在于我们一旦除了 w,顶点信息就不在一个线性空间了。也就是说如果在顶点着色器就直接输出到 NDC 空间, 我们之后没办法得出一个线性的插值。(实际上保留w分量还是可以做到的,不过这稍微便宜了常规管线的做法)
5 顶点着色器到光栅化之间
5.1 Primitive Assembly
我们在操作完所有的定点之后,我们需要把他们根据给定的索引凑成一组一组的三角形。我这里定义了一个三角形的类,里面包含了三个 PixelIn 的值 (也就是顶点着色器的输出结果 ) 。 并且根据我们传入 DrawIndexInstanced 函数的索引三三配对成三角形。
5.2 Face Culling
在这个阶段,光栅化之前,我们会根据我们对管线的设置选择性的抛弃 正面/背面 的三角形。这里使用一个简单的叉乘就可以得到我们输入三角形的方向并进行剔除。
5.3 Clipping
剔除这里一般来说是把完全在裁剪空间外的三角形给去掉。并且如果有三角形一半在外面一半在内部,我们就会在裁剪空间的边缘建立新的顶点 (RTR4 是这样说的 ) ,并且形成两个新的三角形用于替代原本一半在外面的三角形。这样的操作在某些情况会让后面光栅化的部分更适合GPU 操作吧。
这里因为光栅化的部分遍历操作上已经排除了屏幕空间外的像素,所以暂时不考虑建立新的顶点这样的裁剪操作,单纯的就丢弃裁剪空间外的三角形。检查的方法也很简单,只需要对每个顶点的每个坐标分量去检查是否在 [-w,w] 范围内就好了。
5.4 Homogeneous Divide
齐次除法,或者说透视除法这里主要就是把我们裁剪空间的数据移动到 NDC 空间。要注意的是到了 NDC 空间后,我们的插值就会变得非线性。不过当然如果我们保持 w 分量不把他变成 1.0f 的话后续的插值计算还是可以达到一个线性的效果的。
5.5 Screen Mapping
屏幕映射其实没有什么好说的,我们做的就是把 [-1,1] 空间的 xy 坐标转换到屏幕坐标。
在映射之前我们会在管线状态中设置一个 ScreenRect 值表达我们要渲染的宽度和高度,然后再直接的进行一个乘法映射就可以了。
6 光栅化以及像素着色
光栅化是在像素着色器前的一个阶段。以往的部分我们都是操作单独顶点,或者是三个顶点为一组的三角形。在这个阶段我们要把三角形内的所有像素都复制,然后把整个填充了的三角形内的所有像素依次的去提交给像素着色器。
具体流程为:
- 选取三角形所在的矩形并且遍历所有的像素
- 对里面的每个像素进行重心插值计算
- 通过重心插值判断像素(采样点)是否在三角形内
- 根据重心插值决定里面数据的插值
6.1 选取遍历矩形
遍历的矩形选起来非常的简单。这里我们是操作在一个二维的空间中,所以我们只需要找到输入的三个顶点里最大的 x/y 以及 最小的 x/y 就可以去开始我们的采样了。
6.2 重心插值
重心插值的细节这里就不提了,直接参考的 TinyRenderer。 不过像前面提到的事情,透视投影在转换到 NDC 空间之后,我们直接用中心坐标取的差值实际上是在非线性空间中进行的,也就是插值结果会是错误的。所以这里我参考了一下OpenGL 的做法:
\[重心坐标: B=(b_0,b_1,b_2)\\ 三个顶点的位置: p_0,p_1,p_2\\ 正确的重心坐标: B' = \frac{(b_0*p_0.w\ ,b_1*p_1.w\ ,b_2*p_2.w)}{(b_0*p_0.w)+(b_1*p_1.w)+(b_2*p_2.w)}\]实际上就是把所有顶点的 w 分量纳入了插值考量。
重心坐标同时也可以根据里面的值去直接的判断采样点是否在三角形内部,只需要看里面是否有负数就可以了。
6.3 插值
因为前面有铺垫过,我为像素着色器设定的输入是含有 36个 浮点数的数据类型,只需要全部遍历一遍然后用重心坐标计算差值就可以了。
6.4 输出
光栅化阶段的输出的数据类型跟输入是一样的。不过数量则是总共有多少采样点在三角形内。之后我们就可以并行的把这些数据单独的提交给像素着色器了。
7 部分代码
主要提交绘制的函数整体来看是这样:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
void SimpleGLCore::DrawIndexInstanced(std::vector<Vertex> vertices, std::vector<int> indices)
{
if ((indices.size() == 0) || ((indices.size() % 3) ^ 0))
assert(!"Wrong indices size");
// 1. get vertex shader and record vertex data
auto vertexShader = PipelineManager::GetVertexShader();
std::vector<PixelIn> vertexOutputs(vertices.size());
for (int i=0; i<vertices.size(); i++)
{
vertexOutputs[i] = vertexShader(vertices[i]);
}
// 2. primitive assemble using index to group
std::vector<Triangle> triangles;
for (int i = 0; i < indices.size(); i+=3)
{
triangles.emplace_back(vertexOutputs[indices[i]], vertexOutputs[indices[i+1]], vertexOutputs[indices[i + 2]]);
}
// rasterize & pixel shader
// can do multi thread i suppose
for (auto& triangle : triangles)
{
if (BackFaceCulled(triangle))
{
continue;
}
// clipping
if (FrustumClipped(triangle))
{
continue;
}
// homogeneous divide
HomogeneousDivide(triangle);
// screen mapping
ScreenMapping(triangle);
// rasterize
std::vector<PixelIn> pinData = Rasterize(triangle);
//
auto pixelShader = PipelineManager::GetPixelShader();
for (const auto& pin : pinData)
{
float4 p = pixelShader(pin);
Pixel color((Uint8)p.x() * 255, (Uint8)p.y() * 255, (Uint8)p.z() * 255, (Uint8)p.w() * 255);
PipelineManager::GetRenderTarget()->SetValue((int)(pin.pos.x()+0.5), (int)(pin.pos.y()+0.5), color);
}
}
}
8 结果
我这里采用一个不处理输入的顶点着色器,以及输出白色的像素着色器做测试: